Mis anécdotas como programador
Me reconozco como programador; pero no un programador general, pues no domino muchos lenguajes y mis desarrollos han sido en lo que se califica como programación de bajo y mediano nivel.
Los inicios
1984
Conocí el mundo de computación por dos tíos que empleaban computadores personales; uno físico, el otro ingeniero civil. Mi tío físico tenía un Apple II, mientras que el ingeniero un IBM PC con MS-DOS. Fue entonces que comencé a interesarme en los computadores y su programación y comencé a aprender con el único computador al que tenía acceso: el Apple II de mi tío físico, el cual tenía en su casa y, mi tío, muy generoso, me permitía completo acceso; a veces en detrimento de su propio trabajo; el IBM PC de mi tío ingeniero no estaba muy disponible, pues lo tenía en su oficina. La Apple II de mi tío físico la tenía en su casa, razón por la cual era en si el único computador al que tenía acceso.
En 1985, luego de una desilusión sentimental que me hizo comprender el "rol e importancia social de una carrera", decidí estudiar Ingeniería de Sistemas; yo era estudiante de Ingeniería Eléctrica y, aunque era una carrera excelente (ya había cursado algunas materias importantes), no encontraba en ella suficiente oportunidad para vincularme con la computación.
Mi primer lenguaje de programación fue el BASIC de la Apple II de mi tío. Luego este lenguaje me sirvió para otros PC primitivos, por aquel tiempo llamados "clones", que tenían el 8086/88 y las calculadoras de mano CASIO (nunca tuve una HP).
En la Universidad aprendí primero Fortran 77 y luego Pascal. Ambos lenguajes me parecieron excelentes. Como el BASIC era interpretado, la rapidez del Fortran me asombró un poco. Recuerdo con nostalgia mis programas Fortran para calcular determinantes, autovalores y resolver sistemas de ecuaciones lineales. También recuerdo una materia, que me era obligatoria, llamada "Mecánica Racional 10". Era tan automática, y hasta un poco sin sentido, que para lo único que me sirvió fue para programar en mi Casio todos los ejercicios posibles. Bueno, eso me permitió embelesarme con la Profesora y, aparte de aprender (y luego olvidar) mecánica estática, mejorar mis habilidades de programación, pues la solución de cualquier problema requería un paseo por el procedimiento y, si no, entonces la Profesora creería que había plagiado la solución de otro compañero. Como la memoria de la calculadora era muy escasa, tuve que inventar un sistema de abreviaturas.
El Fortran lo aprendí sobre el Burroughs 5900, un mainframe medio, célebre por su arquitectura "pila" (no tenía registros). Las prácticas de programación se realizaban en una sala situada a derecha de la entrada del edificio administrativo. Mis prácticas eran en la mañana, hora en que era probable tener la máquina cargada; consecuentemente, la interactividad era lenta y era tedioso trabajar. Ahora bien, justo detrás de la sala, pero accedida desde otro pasillo, había una salita, silenciosa, con unos 5 terminales disponibles que tenían mayor prioridad que los de las prácticas. Nos metíamos todos los que podíamos y poníamos a un compañero a montar guardia contra el vigilante de la sala, Segundo Quiroz, quien era el terror de los estudiante noveles. Créanme cuando les digo que nadie quería que Segundo los descubriera; era preferible un guardia nacional con peinilla que tener que encarar a Segundo.
Programación de bajo nivel
En 1987 me regalaron el Kernighan-Ritchie sobre el lenguaje C. Como sospecho debe haberle sucedido a muchos otros, este texto cambió mi vida de programador. Una palabra resume al lenguaje C: simplicidad; bondad en general muy apreciable, que en un lenguaje de programación la veo desde tres grandes perspectivas: (1) es muy fácil de aprender, (2) es muy fácil de escribir un compilador y (3) (debido a las dos primeras) su código generado es muy eficiente. Puesto que por aquellos años la memoria era escasa (como 64 Kb) y la velocidad de reloj muuuy leeenta(como 1 Mhz), la eficiencia era algo muy apreciado. Así que me convertí, en la medida de las posibilidades, pues sobre el MS-DOS aún no se conocía un compilador C y requería una máquina Unix, en un programador de C.
Casi paralelamente, aprendí el ensamblador del célebre Z80, pues en mi Escuela habían unos con sus proto-boards y sus periféricos, ya listos, que permitían hacer control discreto. El Z80 era el procesador del Epson QX-10, un PC muy popular y versátil para aquella época. También aprendí la arquitectura y ensamblador de los micro controladores Intel 8048 y 8051.
Por el 88, yo tenía unos algunas bibliotecas en Pascal, en particular rutinas de entrada y salida y, puesto que no quería rehacerlas, traté de encadenarlas con mis nuevos programas en C; no funcionó y la ausencia de documentación me hizo demorar como un mes en descubrir la razón: Pascal pasa los parámetros a las rutinas en orden inverso al C y a la mayoría de los lenguajes. Me decidí, entonces, a estudiar más seriamente sobre ensambladores para los procesadores que para la época manejaba (8086 y Z80), así como los encadenadores (linkers) en Unix y CP/M; no para MS-DOS, pues por aquel tiempo en este sistema no se manejaba el concepto de encadenador.
¿Qué tipos de programas escribía yo para ese ese tiempo? Programas para hacer gráficas y estadísticas para los físicos sobre el QX-10 y CP/M. Los hacía en BASIC porque su biblioteca contenía rutinas gráficas que me ahorraban mucho tiempo. En cierta oportunidad, para una tarea de Servomecanismos (una materia de mi carrera), me encargaron un programa para graficar diagramas de Bode; desarrollé ese programa en BASIC para el MS-DOS porque tenía sólo dos días para hacerlo. Aparte de una buena nota, el programa fue usado por algunos minitequeros de la época para diseñar "cross-overs"; lo que me deparó en alguna que otra fiesta como "arrocero".
Hitos mundiales en sistemas para PC
Hay dos sucesos hitos en mi devenir como programador (así como presumo para el de otros) que creo valen la pena mencionar. El primero de ellos fue la aparición del IDE Turbo Pascal, con su rapidísimo compilador, realizado por Borland (una empresa de software histórica). Por la época. compilar un programa tomaba algunos minutos; con Turbo Pascal era cuestión de 2 o 3 segundos. De allí me quedó demostrado la importancia del conocimiento en el desarrollo de software; Pascal es un lenguaje mucho más complejo que C y el Turbo Pascal lo compilaba increíblemente, mucho más rápido que cualquier otro compilador. El segundo suceso fue el descubrimiento del Amiga de la empresa Commodore. En el mundo del hardware PC, la Amiga fue tan impactante respecto a los Apple, IBM y EPSON como lo fue el Turbo Pascal a la compilación. ¿Por qué estos fueron hitos para mí (y otros)? Por dos razones. La primera era que comparar estos sistemas con los restantes de la época era como comparar un carro de los años 20 del siglo XX con uno de los años 80/90. La segunda más extraña era que, a pesar de su enorme superioridad, estos sistemas fueron vencidos comercialmente por otros mucho más pobres en rendimiento. Curiosamente, esto ha sucedido en otros ámbitos tecnológicos; por ejemplo, en la propia industria automovilística, así como, también, en la aviación. Estos hitos en sistemas computacionales me hicieron aprehender, ya para antes de 1990, que lo perfectamente tecnológico no es garantía de triunfo ni de gloria; más bien, desde otros puntos de vista, no estrictamente comerciales, hasta puede ser contraproducente. Por supuesto, lo perfecto no es puramente en lo técnico; hay otros matices, pero, a pesar de ello, el poder comercial no debería de ser tan decisivo.
Los mediados de los 80, época en que yo era estudiante oficial de pregrado, fue muy interesante para la computación. El mundo PC hizo que el hardware fuese asequible a muchos y los grandes descubrimientos de los 70 estaban implementándose en los PC; aparte de las tecnologías en compilación y sistemas operativos de las cuales acabo de hablar un poco, también estaban gestándose los primeros sistemas PC en bases de datos y en interfaz hombre/máquina orientada a sistemas de ventanas.
En el hardware había una competencia muy extraña en el Motorola 68000 y el 8086/88. Digo muy extraña porque el Motorola 68000 era, con creces, muy pero muy superior, al 8086/88. Ya de entrada esa era la razón por la cual también el Macintosh y el Amiga eran muy superiores, técnicamente, al IBM PC. Sin embargo, el Macintosh era más costoso y, muy importante decirlo, mucho más cerrado que el IBM PC y el Amiga. A pesar de la superioridad en hardware y software que tenían el Macintosh y el Amiga y a pesar de que el Amiga era económicamente y cognitivamente tan asequible como el IBM PC, fue este último el que se impuso y modeló el mundo de hoy.
Brechas y saltos cualitativos
La Escuela de Sistema de la ULA era un poco "obsoleta" en sistemas de archivo y bases de datos (¡y por desgracia aún lo es!). Para mediados de los años 80, el curso de PR-2 era muy bueno, pues era, fundamentalmente, un curso de "Analista de Sistemas" y había que realizar un sistema programado de envergadura, las tecnologías disponibles de recuperación de información en memoria secundaria y PC eran escasas. Para ese entonces, se enseñaban estructuras de datos de los años 60 y 70 (¡y aún hoy en el 2010 se enseñan!) que si acaso eran aplicables a discos duros de alto desempeño, carísimos y por lo general disponibles en "mainframes", pero de difícil aplicación a los lentos "floppy disk". En síntesis, los estudiantes de Sistemas eran capaces de realizar sistemas programados muy buenos, pero no podían manejar eficientemente la alta escala, la entropía de datos y demoraban mucho en encenderse y apagarse, pues el guardado de los datos a disco y su recuperación se hacía muy primitivamente
En el párrafo anterior califiqué a la Escuela de Sistemas con el adjetivo "obsoleto" respecto a las tecnologías de recuperación de información. Las comillas son necesarias porque para la época la ULA era pionera planetaria en esta clase de tecnologías. En efecto, la antigua BIECI (la biblioteca de ciencias e ingeniería) poseía toda una infraestructura de recuperación de información desarrollada enteramente por profesores y estudiantes de la ULA. Lamentablemente, parece que nadie tuvo la idea de llevar aquellas tecnologías al mundo del PC y ofrecérselas al estudiantado, para así posibilitar desencadenar desarrollos masivos. Las veces que me acerqué a preguntar, sentí una especie de recelo en proporcionar información. Huelga decir que eran los años del neoliberalismo frenético.
En interfaces, específicamente en sistemas de ventanas, la Escuela de Sistema sí era realmente obsoleta (y aquí, lamentablemente, es necesario decir que aún lo es, pues de eso no se enseña nada en el pensum común de Sistemas; hay una materia, pero es electiva).
Para atajar alguna eventual réplica peregrina a mis comentarios sobre la obsolescencia de mi Escuela, permítaseme destacar que se trataba de una Escuela de Sistemas, focalizada en los sistemas de control y en la investigación de operaciones, mas no en las ciencias computacionales. Como tal, la computación era más bien instrumento y medio más que campo de estudio. En este orden de ideas, tengo que destacar que la Escuela de Sistema era muy buena, pero no lo suficiente como para formar a un computista de aquel tiempo: adolecíamos de falta soportes para C, interfaz de entrada/salida y manejadores de bases de datos.
Primer salto cualitativo: C en serio
La "obsolescencia" mencionada cambió súbitamente con el surgimiento de varias fuerzas "liberadoras". La primera fue la aparición del Turbo C, cuyo desempeño era mucho mejor que el del Turbo Pascal. La mejor forma para compararlos consistía en escribir el mismo algoritmo en los dos lenguajes, compilarlos y ejecutarlos. Instrumentamos, con dos compañeros más, la transformada rápida de Fourier en ambos lenguajes; nos aseguramos de todo fuese igual (estructuralmente hablando) y al compararlos el Turbo C fue casi el doble de rápido. Nos asombramos de tanta diferencia y, aparte de que un compañero y yo decidimos conmutar a C (el otro se quedó con Pascal), me preguntaba acerca el por qué, si el fabricante era el mismo, la diferencia era tan apreciable. Puesto que tenía experiencia con el ensamblador, Pascal y C, pues lo primero que me ocurrió fue mirar los códigos generados por los compiladores. Fue entonces cuando me di cuenta del porqué de la superioridad del C: no sólo Turbo C generaba código objeto mucho más eficiente, sino que éste era mucho más legible, más fácil de comprender, que el generado por Turbo Pascal.
Segundo salto cualitativo: interfaz en serio
La segunda fuerza liberadora, fue el descubrimiento de un libro sobre Turbo C. Perdí ese libro durante mi estadía en Francia, pero creo que se llamaba, "Turbo C: memory-resident utilities, screen I/O, and programming techniques", de Al Stevens. Por la época, yo daba clases de programación en una compañía de unos amigos muy queridos llamada "Enson". Por circunstancias que jamás comprendí, por aquellos predios apareció el libro de Stevens y, al ojearlo, me di cuenta que contenía toda la implementación en C de una biblioteca de entrada y salida; en particular, un sistema completo de ventanas. El libro pertenecía a un Profesor de la Facultad de Ciencia. Unos días después, un compañero de estudios logró "tomarlo prestado", lo fotocopiamos, comenzamos a estudiarlo y transcribir los códigos que aparecían en el libro (el libro venía con un floppy, pero éste no se nos había prestado).
Durante este tiempo, ya me era clara la importancia del software libre. Huelga decir que el libro de Stevens era muy ocultado; el Profesor de Ciencias se negaba a compartirlo y que me compañero (él lo decía, yo le creía y aún lo creo) tuvo que hacer maromas para "prestarlo" y fotocopiarlo. Mi vinculación con el software libre está escrita por separado en este enlace software libre en el cual se narran más detalles.
El sistema de ventanas
de Al Stevens fue muy enriquecedor. Empero, tenía un
defecto bastante severo el, cual, para plantearlo, requiero explicar
un poco sobre el manejo de ventanas. Digamos que por cada ventana se
tiene que anotar, entre otras cosas, sus coordenadas en la pantalla y
una matriz de los píxeles o caracteres que ésta contiene. Consideremos
3 ventanas como las de la figura mostrada 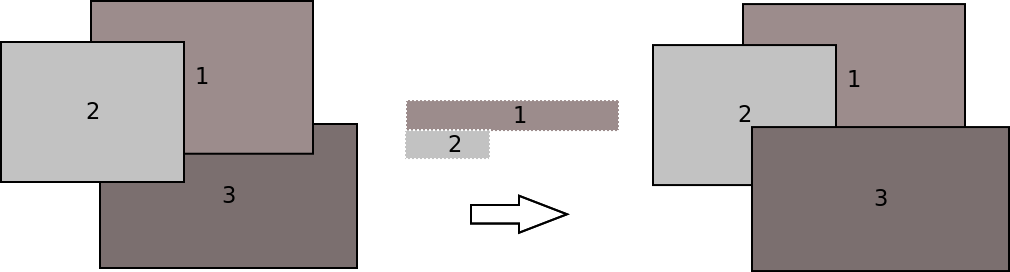 . En el lado
izquierdo, la ventana 2 está completamente visible, tapando una
sección de la ventana 1 y otra de la ventana 2. Ahora supongamos que
"clickeamos" sobre la ventana 3; lo que nos conlleva a que ésta se
muestre enteramente, tapando una parte de la ventana 2 y dejando como
se muestra en el lado derecho de la figura. Cuando ocurre ese "click",
hay que dibujar enteramente la ventana 3. Stevens usaba una rutina que
examinaba cada símbolo de la ventana 3 y calculaba si éste estaba o no
oculto; la operación era proporcional al número de símbolos que de la
ventana 3 estuviesen tapados por las otras ventanas, cuyas áreas
aparecen en el centro de la figura. Claramente, este esquema era muy
ineficiente, pues recorría todos los símbolos de la ventana 3 y, por
cada uno de ellos, se calculaba su intersección con el resto de las
ventanas. En la medida en que hubiesen más ventanas en pantalla, más
lento era calcular la intersección de cada símbolo.
. En el lado
izquierdo, la ventana 2 está completamente visible, tapando una
sección de la ventana 1 y otra de la ventana 2. Ahora supongamos que
"clickeamos" sobre la ventana 3; lo que nos conlleva a que ésta se
muestre enteramente, tapando una parte de la ventana 2 y dejando como
se muestra en el lado derecho de la figura. Cuando ocurre ese "click",
hay que dibujar enteramente la ventana 3. Stevens usaba una rutina que
examinaba cada símbolo de la ventana 3 y calculaba si éste estaba o no
oculto; la operación era proporcional al número de símbolos que de la
ventana 3 estuviesen tapados por las otras ventanas, cuyas áreas
aparecen en el centro de la figura. Claramente, este esquema era muy
ineficiente, pues recorría todos los símbolos de la ventana 3 y, por
cada uno de ellos, se calculaba su intersección con el resto de las
ventanas. En la medida en que hubiesen más ventanas en pantalla, más
lento era calcular la intersección de cada símbolo.
Al estudiar detalladamente el texto de Al Stevens, aprecié este problema de desempeño y decidí rehacer la biblioteca con tres añadiduras. La primera fue que el desplegado en pantalla se hacía por zonas de intersección; tal como aparece en el centro de la figura. La segunda fue añadir menús a la biblioteca. Finalmente, le añadí reconocimiento de todo el hardware gráfico que existía para ese tiempo; Al Stevens sólo consideraba (si bien recuerdo) VGA y EVGA.
Tercer salto cualitativo: dBase-II
Lo único que faltaba para que el mundo del PC fuese equiparable al de los mainframes y minicomputadores llegó con el dBase-II; un manejador de bases de datos, con su lenguaje e intérprete. No puedo asegurar que los mismo ocurrió en otras latitudes (presumo que sí), pero, en Venezuela, el dBase-II y sus derivados (Clipper , FoxPro, etc.) fue toda una revolución y, en lo personal, casi me hizo abandonar mi carrera para dedicarme a realizar sistemas programados.
Con dBase-II obtuve dos trabajos interesantes, que luego me depararon en otros trabajos. El primero fue en una fábrica de ropa, en el cual se me encargó el inventario y producción, luego la contabilidad y un programa de corte "óptimo" de telas. Aunque el inventario es hoy un programa clásico, éste no es tan fácil como parece cuando el consumo de materia prima no se puede objetivar o cuantificar exactamente; cual es el caso de la confección de un vestido, en que el consumo de tela depende del modelo, de las tallas y de las cantidades de vestidos que se deseen. Sorpresivamente, este fue mi primer encuentro práctico con la investigación de operaciones y con la geometría computacional, pues se debe cortar la tela de manera tal que se minimicen los desperdicios por retazos. Forjé, muy primitivamente, un repertorio de polígonos y combinaciones de concatenaciones entre ellos y formulaba la optimización para formular una matriz para el simplex y ejecutarlo. Lo fastidioso es que era en dBase-II y no en algo como Fortran o C. Si bien creo que mis polígonos desperdiciaban tela, estoy seguro que era mejor que hacerlo a mano. Con el sistema de inventario y producción me fue bien. Con el de optimización, aunque funcionaba, su interfaz era tan difícil y fastidiosa que sólo yo era capaz de usarla. En cuanto a la contabilidad, bueno, este fue mi primer fracaso. La contabilidad, aunque no lo parezca en apariencia, es bastante compleja y los contadores son muy eficientes y exigentes.
El segundo sistema de interés fue para formulación seguimiento de ejecución y cobros y valuaciones de obras civiles en electricidad. Este sistema lo realicé enteramente en dBase-II y tiempo después lo compilé en Clipper. Digamos que fue un "éxito" y lo propagué (sin mucho éxito, pues tenía demasiada competencia), a las obras civiles tradicionales. Por otra parte, me percaté de muchas cosas interesantes sobre el negocio en una obra civil. Por ejemplo, mi sistema tenía que permitir, arbitrariamente, inflar los precios de un presupuesto de obra a un porcentaje parámetro de la obra; después, cuando venía el cobro, había un proceso llamado "valuación", legal, que legitimaba subir aún más el precio.
La gente de obras eléctricas me puso en contacto con un hotel de envergadura. Fue entonces que diseñé un sistema de gestión hotelera; sólo la gestión de habitaciones y huéspedes, pues un hotel tiene mucho, pero mucho más cosas que automatizar. Fue un sistema sencillo, realizado en unos 15 días, que estuvo operativo al menos durante unos 3 años.
Un antiguo Profesor de mi carrera fue designado en la Oficina de Relaciones inter-institucionales de mi Facultad. Él me pidió ayuda para que le realizase un sistema que gestionase las pasantías de los estudiantes de la Facultad. Recuerdo bien que lo hice en menos de una semana, pues para entonces nos encontrábamos en las vísperas de las pasantías y se requería con urgencia. Era un sistema sencillo, pero automatiza la gestión de cada estudiante, desde el momento en que ingresaba al sistema, se aprobaba su pasantía, se le expedía (por el sistema) su carta de presentación hasta que la culminaba. Creo que fue en 1988 que realicé este sistema. A mi regreso de mi doctorado, en 1998, el sistema aún funcionaba.
Un problema que tenía el dBase-II era que, puesto era interpretado y carecía (o yo no los conocía o no tenía la suficiente habilidad para hacerlo) de mecanismos explícitos para emplear componentes de otros sistemas, pues era muy difícil rehusar componentes. Ese problema fue rápidamente paliado cuando apareció el Clipper, cual creaba unos índices para las tablas muy buenos y compilaba. Al disponer de un código objeto, pues ya podía yo interconectar lo que quisiese, a veces con ciertos trucos en ensamblador (inyección de llamada a procedimiento) o con mecanismos que tenía el Clipper para interconectarle rutinas de otros lenguajes.
Los "ingenieros de software" o, mejor dicho, los gerentes que nunca han codificado, mucho hablaron después sobre componentes, su reutilización y demás cosas. Si bien hacer ordinarios los procesos de fabricación es sumamente importante en toda ingeniería (y eso es parte de la del software), los gerentes de mi Escuela no tenían el conocimiento para investigar seriamente sobre mecanismos de reutilización. Por eso debieron de esperar que llegasen un montón de cosas de allende: java, CORBA, etc., para así sí poder hablar de componentes y reutilización. Lo cómico del asunto, es que los programadores serios siempre, pero siempre, reutilizan componentes, pues ¡a la gente seria y con sentido común no le gusta repetir el trabajo! y, dentro de esa categoría, nos encontramos muchos programadores. Por otra parte, el qué sobre la reutilización ya se conocía bien; así que, ¿por qué tan pocos se preocupaban sobre el cómo? es decir, sobre el mecanismo.
Por la época en que hice el sistemita para la ORI, yo estaba pensando seriamente dedicarme a realizar sistemas programados; a entrar en el mercado del software y a ganarme la vida con ello. Pero este sistema me hizo aterrizar en dos realidades. Primera, el hacer un sistema dentro del mundo universitario me hizo reflexionar sobre la importancia de terminar mi carrera. Segunda, puesto que para aquel momento yo ya estaba convencido de la importancia del software libre, yo sentía que meterme en el mercado del software me sería muy difícil; además, eran los años del neoliberalismo frenético; a veces yo creía que la razón por la cual yo vendía sistemas no sólo era que éstos fuesen eficaces y desarrollados en muy corto tiempo, sino que eran demasiado baratos. Así las cosas, decidí dejar de "matar tigres" y retomé intensivamente mi vida de estudiante, que no la había abandonado ni desmejorado, pero sí la había ralentizado.
Cuarto salto cualitativo: bases de datos en serio
El amigo Al Stevens nos entregó otra contribución, proveniente del mismo Profesor de la Facultad de Ciencias y adquirida por nosotros del mismo modo: o sea, fue temporalmente prestada para fotocopiarla. Se trataba de otro libro titulado "C Database Development", el cual contenía los detalles de implementación de un sistema de tablas relacionales e índices. Un asunto que sí se estudió bastante en mi Escuela fue el de la recuperación de información; a ese tenor, habían muchas implementaciones de sistemas de tablas e índices; pero muchos estaban en Pascal, no estaban adecuadamente organizados en biblioteca y no eran directa y libremente asequibles.
Así que cuando descubrimos el libro de Al Stevens ya teníamos una biblioteca en C con que hacer todo lo que hacía el dBase-II. Eso, aunado a las bibliotecas de interfaz, nos permitía hacer programas de alto desempeño.
Con esa biblioteca realicé rápidamente un sistema rápido para una librería. Le legué el sistema a un amigo cuando regresé intensivamente a la Universidad,Quinto salto: el laboratorio de servomecanismos
Los sistemas de control merecen una mención particular en mi devenir como programador. En la Escuela de Sistemas se estudiaba muy bien los sistemas de control y, puesto que su instrumentación requiere de programación de bajo nivel, yo me sentí convocado. Los ejercicios escolares con los micro-controladores 8048 y 8051 y los computadores analógicos me enseñaron a programar muy eficientemente. Hoy en día es mucho más fácil hacer sistemas embebidos, pues hay mucha más velocidad y memoria. Pero para aquellos tiempos, instrumentar un algoritmo de control en tan poquita memoria requería conocer y entender muy bien sobre los escasos recursos que se disponían y esmerarse en hacer programas muy eficientes: mínimo consumo de memoria, máxima velocidad. Inclusive con el Z80, que encajaba como micro-controlador, había que ser muy eficiente.
En una de las cajitas que tenía el laboratorio de servomecanismos, instrumenté un algoritmo para manejar un carrito en una pista de juguete, con mis propias heurísticas. El algoritmo podía vencer a un humano no muy versado en la conducción, pues nunca pude derrotar a un humano que supiese manejar bien.
En este laboratorio conocí a muy buenos programadores. Recuerdo, con nostalgia, la dedicación y disciplina de Felix Blanco con el Z80; llegaba muy temprano para estar seguro de tener el procesador y cuando yo llegaba, pues ya él tenía todo listo. También recuerdo a Vladimir Ramirez y su péndulo inverso así como a Nelson Lomelli y su brazo mecánico perfectamente controlado por jostick desde un Epson QX-11 o Ábacos. Nelson también nos legó un recuerdo que creíamos pertenecía al mundo de las comiquitas: la explosión del laboratorio; nunca supe cómo ni porqué, pero el QX-11 explotó, y feo, todo el techo del laboratorio quedó negro.
Por supuesto, este laboratorio no hubiese sido lo que fue, ni sería lo que es, sin Alfredo. Sea esta mención un reconocimiento por su entrega y paciencia.
Hablando de laboratorios, merece una muy reconocida mención en esta memoria otro laboratorio, ubicado en la Facultad de Ciencias, cual creo era presidido por Geza Holzhaker. Como lo reseño en mis notas sobre el software libre, en la Facultad de Ciencias había buenos desarrollos, pero algunos de profesores eran demasiado egoístas, no compartían sus programas ni los enseñaban a hacer. Bueno, aunque no lo conocí bien, dos compañeros míos trabajaban con Geza. Fue por él, ayudando a mis compañeros, que aprendí sobre el Motorola 68000. Yo diría que Geza exhibía para aquella época lo que hoy se conoce como el espíritu hacker. Para aquellos años (85 y 86), Geza hacía procesamiento de imágenes, asunto cotidiano hoy, pero poco conocido para entonces.
Sexto salto: Sistemas Operativos
Como ya no tenía cupo de créditos, tuve que entrar de oyente al curso de Sistemas Operativos con mi amigo y maestro Gerard Páez. Este curso es un hito en mi vida de programador, fundamentalmente por una razón: el libro texto era el Tanenbaum, el cual contenía en anexo el código fuente, completo, de un sistema operativo, rudimentario, pero con gloriosos fines didácticos, llamado Minix, pues aprender Sistema Operativos con él era casi como hacer un sistema operativo.
De los libros Al Stevens, yo ya estaba acostumbrado a transcribir código. Pero el Minix, eran palabras mayores, por su escala y complejidad. Un sistema operativo ya pertenece a la categoría de gran sistema.
Transcribí completamente Minix, pero me encontré con un obstáculo: tenía que escribir en el "sector de boot" (o MBR Master Boot Record) de un floppy (no tenía disco duro y si lo hubiese tenido creo que de todos modos no lo habría tocado) la secuencia de arranque de Minix. Yo había aprendido algo de ello, del libro "Peter Norton Programmer's Guide" de su autor homónimo (y en aquel tiempo, decía yo, snobista), Peter Norton, cuando durante un trabajo de Ingeniería del Software nos invadió el virus del ping-ping, tuve que escribir una rutina que restauraba el MRB. No se crean que fue algo muy genial; sólo consistió en embeber en un arreglo char sector [] = { 0xXX, 0xXX, ....... 0 } el volcado de un floppy sano e invocar las interrupciones de I/O para el disco (toda esa información estaba en el libro de Peter Norton).
Logré "bootear" Minix "parcialmente". A veces el sistema fallaba y la verdad nunca supe exactamente por qué; tal vez había un bug o tal vez yo había cometido un error de transcripción (era muy probable). El caso es que el sistema se caía aleatoriamente.
De los que refiero como mis saltos cualitativos, con todo lo arduo que fue y lo frustrante que era cuando se caía. Minix representa para mí el salto más largo, cualitativamente hablando. Aprehendí, sin percepción consciente, principios de diseño de sistemas computacionales como el extremo-a-extremo y los micro-kernels, así como de hardware, en particular I/O, y, obviamente, aprendí de sistemas operativos. Después de este curso, concluí que era una gran lástima que el Motorola 68000 no le haya ganado a los Intel, o que Microsoft u otros se hayan casado con Intel, pues, de no ser así, la mayoría de los sistemas computacionales hubiesen sido mucho mejores y el Minix tal vez sería el sistema libre de hoy en día.
Después de Minix me sentí un programador disciplinado en el código pero desordenado en la vida (allí comenzó seriamente mi vida de noctámbulo).
Séptimo salto: Sistemas no-lineales
Una materia que también me marcó bastante fue "Sistemas de Control No-lineales". Esta materia trataba de modelos no-lineales y técnicas para controlarlos; o sea, objetivamente, un conjunto de ecuaciones diferenciales, no lineales, y las técnicas para aproximarlas a un sistema lineal de ecuaciones de estado. La materia fue impartida por Hebert Sira, un Profesor muy reputado a nivel planetario. El programa tradicional se ceñía a enseñar técnicas matemáticas para aproximar un sistema no-lineal a uno lineal en un rango, por lo general estrecho, del estado. Pero ese semestre (1989 o 1990) se introdujo un nuevo método: la linealización exacta. Este método, originado desde la geometría diferencial, transformaba cualquier sistema no lineal en un sistema de ecuaciones de estado exactamente lineal. Según, digamos, el carácter no lineal del sistema primigenio, todo su no-linealidad se iba a una fórmula sin diferencial.
Pero habían dos problemas. El primero es que había que derivar y derivar hasta lograr la exactitud ... y se derivaba anidadamente hasta la n-ésima derivada según la cantidad de variables de estado que tuviese el sistema. El segundo problema era que la fórmula hacia donde se iba la no-linealidad era monstruosamente larga y compleja.
¿Por qué esta materia fue un salto para mí?. Enumero brevemente las razones:
- Derivar tanto, aparte de lo tedioso y lo sumamente cuidadoso que había que ser para no equivocarse, sobrepasaba el ánimo de cualquiera. En otras palabras, este era un problema computacional. De allí surgió mi primer encuentro con los sistemas de cálculo simbólico tipo Maple (que estudié internamente muy bien en mi maestría), Mathematica, Axiom y Maxima de hoy en día y con el sistema de ese entonces llamado Reduce.
- Conocí el Simnon, un sistema de especificación de sistemas de ecuaciones diferenciales y su simulación. Ignoro el paradero de este sistema; mis búsquedas no lograron dar con él, pero, en mi opinión, Simnon no sólo representó un salto cualitativo para mí, sino, también, para la comunidad de sistemas de control. Tenía un lenguaje de especificación de sistema muy fácil y las resolvía en un parpadeo. La interacción de un diseñador de sistemas de control cambió notablemente; uno ajustaba parámetros, cambiaba controladores y Simnon los graficaba rápido y juntos, de manera tal que uno tenía una apreciación comparativa global.
- La fórmula sin diferencial hacia donde se desplazaba la
no-linealidad tiende a ser extremadamente larga y compleja; tanto que
puede hacer que los otros métodos, de linealización aproximada o
extendida, comparativamente hablando, sean más atractivos; por lo
mucho menos costosos que son en consumo de recursos e, inclusive, por
su simplicidad. En síntesis, hacer un controlador basado en
linealización exacta plantea un desafío computacional (el cálculo de
la fórmula) de cara a otros métodos, pues para calcular muy
rápidamente la laaaarga formula se requiere mucha más memoria y CPU
que con otros métodos.
No sé que tanto haya cambiado este panorama, pero, como estaba entre mis consideraciones de tesis instrumentar un controlador basado sobre linealización exacta, me puse a estudiar seriamente el recién propuesto Fortran 90, el EISPACK, predecesor del actual LAPACK, BLAS y, muy en particular, sobre el aprovechamiento del cache en arquitecturas RISC para cómputos numéricos. Lo ladilla era que el 8086/88 era demasiado lento sin un co-procesador matemático.
Este aprendizaje me preparó bastante para la computación de alto rendimiento, área a la que me abocaría unos años después.
Una idea especulativa que tuve en aquel entonces, y que aún intuitivamente conservo, consiste en estudiar si no es menos costoso calcular la fórmula en cuestión con medios analógicos.
Por aquella época regresé al Pascal, pues le codifiqué algunas cosas a un Profesor de Programación que estaba realizando su trabajo de ascenso. En el mismo tenor, también ayudé con la programación a mi amigo Marcelino en su tesis de pregrado.
Último salto: Sinergia_ω
Después de evaluar algunas propuestas, decidí hacer una tesis con Charles Páez, Profesor de la Escuela de Ingeniería Eléctrica, muy versado en computación. Vale destacar que de Charles aprendí mucho, pero mucho, de computación, formalmente hablando, pues con él pude apreciar lo que es aprender con rigor y disciplina.
Charles me propuso la realización de un sistema de especificación y validación automática de protocolos de comunicación. Yo conocía un poco de este tema, pues para ese entonces yo ayudaba a Marcelino, un compañero de estudios, con el lenguaje C y la programación de un sistema relacionado.
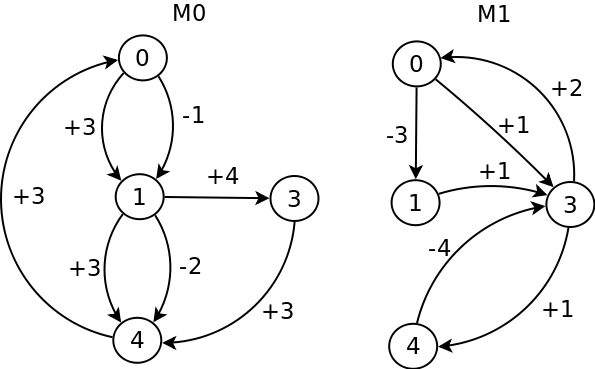
La manera más concisa que encuentro para introducir el asunto es través de la figura que se muestra tomada del célebre artículo precursor de este campo de Zafiropulo et al. En ella aparecen 2 muy simples máquinas de estado finito, denominadas M0 y M1. Cada máquina transita a un estado según envío o recepción de un mensaje. Los estados y los distintos tipos de mensajes están enumerados; un signo positivo indica recepción de mensaje, mientras que uno negativo envío.
Aunque estas especificaciones son algo irreales, por su simplicidad y bajísima escala, éstas son muy ilustrativas de los diversos tipos de errores que pueden aparecer en el diseño de un protocolo. Veamos:
- Deadlock: supongamos que ambas máquinas se encuentran en el estado 0. Ahora supongamos que M0 transmite 1 y M1 transmite 3. Al M0 enviar 1, pasa a su estado 1 mientras que M1, al enviar 3, también pasa a su estado 1. Ahora, bajo recepción de los mensajes, M0 pasa al estado 3, mientras que M1 al estado 3. Es esta situación el sistema se encuentra "muerto", pues ambas máquinas sólo esperan recibir mensajes.
- Recepción inesperada: desde el mismo estado inicial 0, supongamos que M1 transmite 3 y pasa a su estado 1. M0 lo recibe y pasa a su estado 1. Ahora supongamos que M0 envía 2. En este caso, M1 (que está en 1) recibe 2, el cual no está especificado. Si M1 tiene un consumo de mensajes FIFO, entonces M1 se bloqueará para siempre.
- Código muerto: un "código muerto" es una sección de un programa que nunca se ejecuta. Si bien no se considera un error grave, sí evidencia mala práctica en especificación (y programación). En términos de un autómata, cualquier transición que jamás sea ejecutada se corresponde con un código muerto. Este es el caso del estado 3 de M1, el cual ¡jamás será alcanzado!
- Capacidad de los canales de comunicación: partiendo desde
estado inicial 0 en ambas máquinas, supongamos la siguiente
secuencia de eventos:
- (**) M0 transmite 1 y 2 seguidamente; lo que hace que M0 quede en el estado 4.
- M1, antes de recibir mensajes, transmite 3 y pasa al estado 1.
- M0 recibe el 3 y se repite desde (**)
Nótese que para se pueda dar correctamente esta secuencia de eventos M1 requiere una capacidad de cola de mensajes de al menos 4, pues, si no, entonces se perderán algunos mensajes.
Conocer la mínima capacidad de encolamiento de cada máquina es sumamente importante para diseñar un sistema.
Hay otras clases de errores, notablemente el livelock, cual consiste en la posibilidad de que el sistema global (el compuesto por todas las máquinas) se quede transitanddo en cadenas de estados sin salir de ellos. En este caso, no se trata de un deadlock, pues el sistema continua ejecutándose, pero podría ser un serio error que comprometa el que sistema alcance otros estados.
Aunque estas ideas fueron inicialmente concebidas para los protocolos de comunicación, éstas son completamente aplicables (y en efecto se aplican) al estudio de las relaciones entre los componentes de cualquier clase de sistema, pues cualquier tipo de interacción entre dos o más componentes puede interpretarse como una transmisión de mensaje; por ejemplos, hardware, componentes de software, etc..
Los errores descritos son "sintácticos" en el sentido de que son cosas que un sistema no debe contener, pues, parafraseando al célebre ingeniero Edward Murphy, "si algo puede salir mal, entonces saldrá mal". Hoy en día esta máxima, proveniente de la ingeniería aeronáutica, es aplicable al resto de la ingenierías, la del software incluida ........ Bueno, con algunas excepciones, pues, me resulta muy curioso que nuestros "ingenieros del software" se preocupan por metodologías y por gastar bastante papel y tinta con dibujos de pelotitas, cuadrados y flechas, pero nunca se preguntan cómo se garantiza si el sistema es correcto y si hace lo que se presume que debe hacer.
| Estado global | Estado M0 | Estado M1 | Canal M0 | Canal M1 |
| 0 | 0 | 0 | ||
| 1 | 1 | 0 | 1 | |
| 2 | 1 | 2 | ||
| 3 | 2 | 2 | 2 | |
| 4 | 2 | 0 | ||
| 5 | 2 | 1 | 3 | |
| 6 | 0 | 1 | ||
| 7 | 1 | 1 | 1 | |
| 8 | 2 | 1 | 2 | |
| 9 | 2 | 0 | 2 | |
| 10 | 1 | 1 | 1 | 3 |
| 11 | 1 | 2 | 3 | |
| 12 | 2 | 2 | ||
| 13 | 2 | 2 | 2 | 3 |
| 14 | 2 | 0 | 3 | |
| 15 | 0 | 2 | 2 | |
| 16 | 1 | 2 | 1 | |
| 17 | 2 | 1 | 1 | |
| 18 | 2 | 1 | 2 | 3 |
| 19 | 0 | 1 | 3 | |
| 20 | 1 | 1 |
Si un sistema no contiene errores sintácticos, entonces decimos, por expresarlo de forma objetiva, que el sistema es correcto; o sea, que no fallará a causa de que se bloquee, se estanque en un ciclo aleatorio o en efecto infinito, cuyos canales de comunicación no serán jamás saturados y que no contiene partes inútiles, que nunca se ejecutarán.
Pues bien, mi tesis fue el diseño y realización de Sinergia_ω. Un sistema completo que permitía a un diseñador de sistemas especificar iterativamente un sistema de máquinas comunicantes y validar automáticamente que el sistema como un todo no contenga errores sintácticos o semánticos. En caso de contener errores, el diseñador podía modificar la especificación según su conveniencia y repetir el proceso de validación hasta que alcance sus criterios de conformidad.
La técnica empleada para la búsqueda de errores sintácticos consiste en construir el "autómata global" del sistema completo. Cada estado de este autómata está conformado por los estados de las máquinas y los contenidos de sus canales comunicación. Por ejemplo, la tabla ilustra los estados globales del sistema compuesto por las máquinas M0 y M1 previamente mostradas para una capacidad de canal de una unidad por máquina. Del mismo modo, el autómata global es mostrado en la figura; los estados en rojo son estados de error.
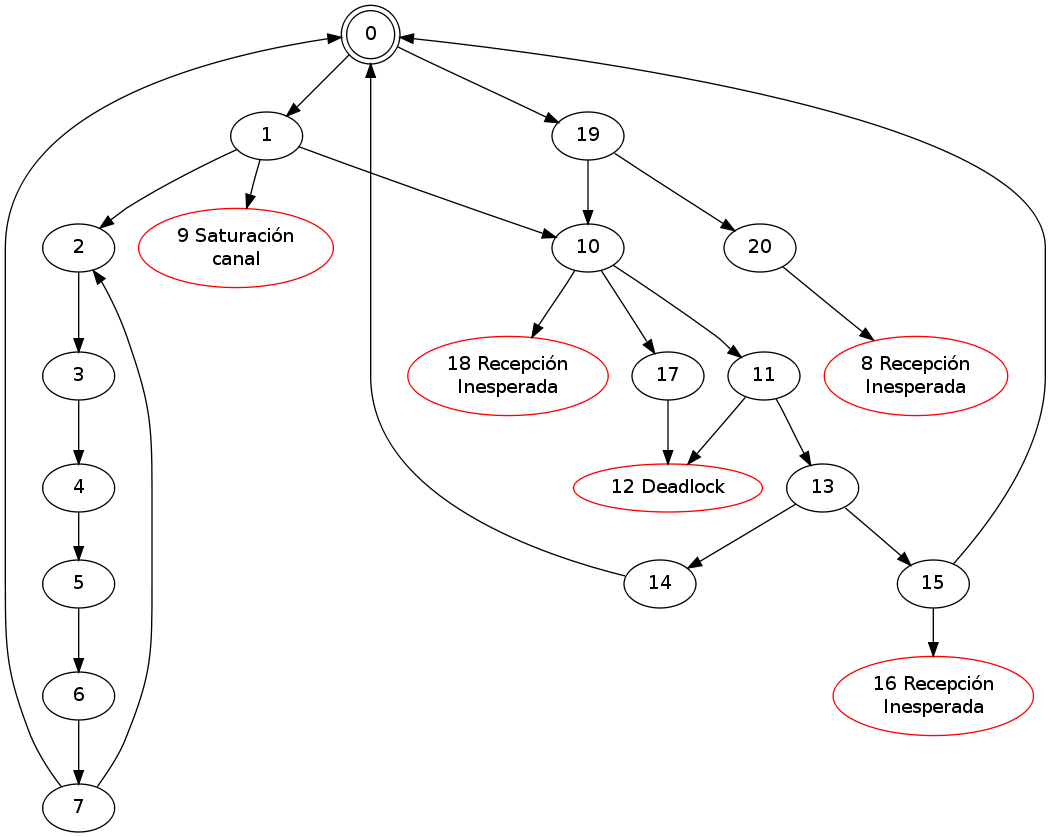
Con el estado global es posible detectar los errores. Las recepciones inesperadas y las saturaciones de canales pueden detectarse en línea durante el cálculo. En el ejemplo, las recepciones inesperadas corresponden a los estados 8, 16 y 18; mientras que la saturación de canal al estado 9. Un deadlock es un estado sin sucesor y con los canales vacíos, cual es el caso con estado 12. Un código muerto se detecta buscando cuáles estados particulares de las máquinas no aparecen en el autómata global. Un livelock es un ciclo dentro del autómata global.
Como se ve, el cálculo del autómata global permite automatizar la búsqueda de errores sintácticos. Hay, sin embargo, algunas consideraciones muy importantes, de índole restrictivo, respecto al cálculo de los estados globales:
- Los estados se guardan en una tabla hash. Cuando se calcula un nuevo estado, se busca en la tabla; si se encuentra, entonces se anula su cálculo pues éste y su subsecuente cadena de estados ya ha sido calculada.
El conjunto de estados globales es subconjunto de los productos cartesianos de los estados de las máquinas y los canales. En el ejemplo, la cantidad máxima de estados está acotada por 4 x 4 x 2 x 2 = 64; sólo para 2 máquinas, de 4 estados cada una, con capacidad de canal unitaria y 2 tipos de mensajes por máquina. La más sutil modificación aumenta la cantidad de estados con tendencia exponencial. Por ejemplo, si la capacidad de los canales se eleva a 2, entonces la cantidad máxima de estados está acotada por 4 x 4 x (2x2) x (2x2) = 256. En palabras más concisas, la cantidad de estados globales aumenta exponencialmente con la cantidad de estados de las máquinas, las capacidades de los canales y las cantidades de máquinas.
Consecuentemente, para el estudio de un sistema real, se requiere muchísima memoria para guardar los estados globales y bastante CPU para calcular rápidamente.
Para la época en que realicé este trabajo, la máxima cantidad de memoria era de 640 Kb. Así que ya me era muy claro que había que encontrar formas de aprovechar al máximo la cantidad de memoria. Apliqué varias técnicas:
- Puesto que a menor cantidad de estados por máquina menor cantidad de estados globales, cada máquina es minimizada.
- Se aplica una primera fase de comprensión básica consistente en representar los estados de máquinas y valores de mensajes con la mínima cantidad de bits. Aquí sí resulto una enorme ventaja el 8086/88 respecto a los RISC SPARC y otros procesadores RISC que dificultaban el tratamiento de bits.
- Reducción de cadenas sucesivas en el autómata global; esto es reducción de orden parcial. Por ejemplo, Una vez calculados los estados 2 y 7, así como conocidos sus estados sucesores, entonces la cadena puede sustituirse por un estado reducido, pues ya se sabe que desde otro estado global. Parecido sucede con la cadena 19->20. Así, el autómata global anterior se reduce al mostrado.
- Compresión de Huffman para el autómata global: a los bytes en bruto que conformaban los estados globales los comprimía mediante el algoritmo de Huffman. Para ser sincero, esta técnica tuvo éxito parcial; a veces comprimía bien, otras veces aumentaba el consumo de memoria.
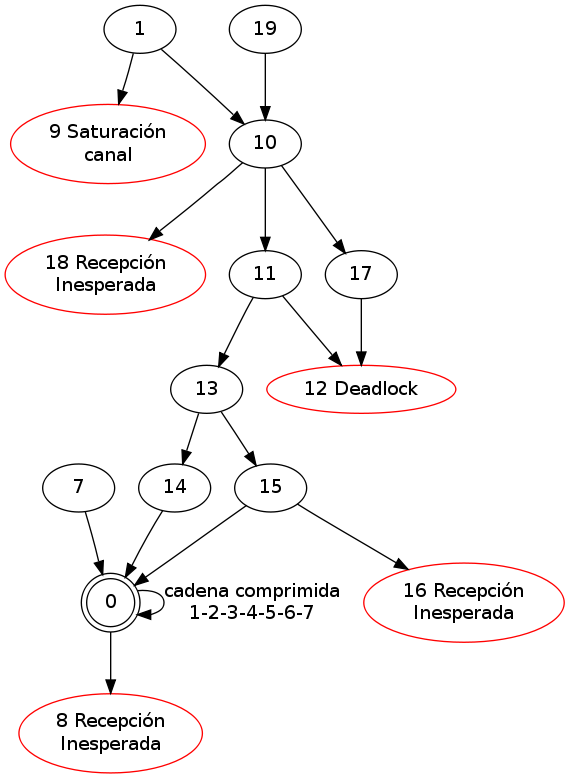
Los autómatas globales de esta página fueron generados por
Graphviz, el
cual no existía para esa época. Para dibujar el autómata global, tuve
que apelar a visualizar el árbol abarcador del autómata global según
el recorrido en profundidad. El resultado es mostrado en la siguiente
figura.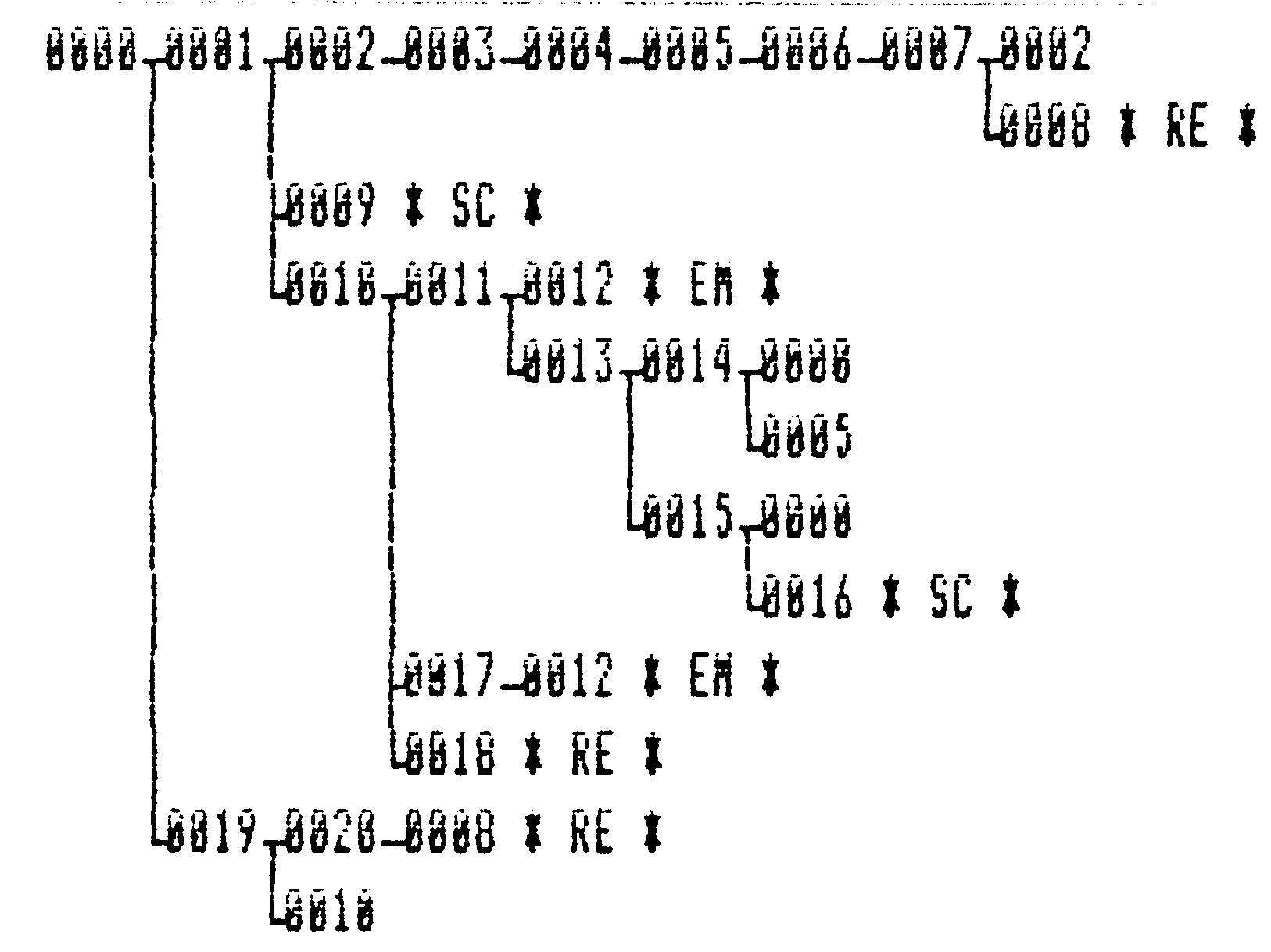 . Logré un algoritmo para visualizar el árbol por
pantalla, pero, más importante aún, para imprimirlo genéricamente,
independientemente de la escala; lo que sí se requería es papel en
caso de que el sistema tuviese muchísimos estados.
. Logré un algoritmo para visualizar el árbol por
pantalla, pero, más importante aún, para imprimirlo genéricamente,
independientemente de la escala; lo que sí se requería es papel en
caso de que el sistema tuviese muchísimos estados.
Hasta aquí, he explicado qué es la correctitud o validez sintáctica y cómo ésta se trata computacionalmente. El que un sistema sea correcto no implica que éste haga lo que se presume debe hacer. ¿Existe alguna manera de verificar automáticamente que la especificación de un sistema se corresponda con uno que siempre haga lo que se diseñó deba hacer? Si existe, entonces, ¿cómo hacerlo?
Antes de responder las preguntas anteriores, es interesante notar que, como todo autómata en el sentido computacional, una máquina componente de un sistema puede caracterizarse por un lenguaje subyacente. En los ejemplos dados, los autómatas son de tipo 3, claramente caracterizados por expresiones regulares equivalentes. Así, es posible substituir cada máquina por un lenguaje o gramática que lo describa. Más fascinante aún, es posible conocer el lenguaje que fluye por un canal de comunicación -o por cada cola de mensajes de una máquina-. Aquí aparece, de forma objetiva, un primer indicio de vitalidad semántica del sistema: si el lenguaje por el canal es finito, entonces podemos concluir que la máquina tendrá una cantidad finita de transiciones; en otras palabras, que la máquina se bloqueará. Si esto sucede con todos los canales, entonces podemos concluir que el sistema total se bloqueará.
A veces un estado muerto de una máquina es marcado como "final"; en este caso, el estado expresa el logro de algún fin y es posible que no se desee que interactúe más. Así, si el sistema se bloquea en solo estados finales, entonces no se considera un error. Pero muy a menudo un estado final se transiciona hacia el estado inicial, a efectos de que la máquina y el sistema global estén listos de nuevo para continuar su trabajo.
Del mismo modo que para una máquina componente, el autómata global también tiene un lenguaje asociado. Así las cosas, una primera forma, lingüística, de ver si un sistema cumple su fin, es ver la expresión regular global (del autómata global) y verificar que:
El último término debe corresponderse a uno que sólo contenga estados finales. Llamemos F a tal estado (compuesto de palabras, no de estados de las máquinas). En sentido simétrico, si llamemos I al estado inicial, entonces una expresión válida tiene forma genérica I....F.
La expresión no puede contener intercalada una estrella de Kleene * o un más + unario, pues si así sucede, entonces es posible que el sistema permanezca iterando sin que alcance el estado final. Por ejemplo, la hipotética expresión regular global Iabcd(fjy + ds)ba(hy+wuq)*saF no es deseable, pues indica que el sistema puede permanecer infinitas veces iterando en (hy+wuq)* antes de llegar al estado F.
Que sólo aparezca el operador unario + al final de la expresión.
En síntesis, un sistema eficaz, que cumple su cometido, debe tener expresión regular global con forma (I ..... F)+, sin * o + unario intercalado; es decir, parte desde el estado inicial I y alcanza el estado final deseado F sin posibilidad de estancarse en un livelock. De allí, el sistema deviene listo de nuevo para "infinitamente repetir el trabajo".
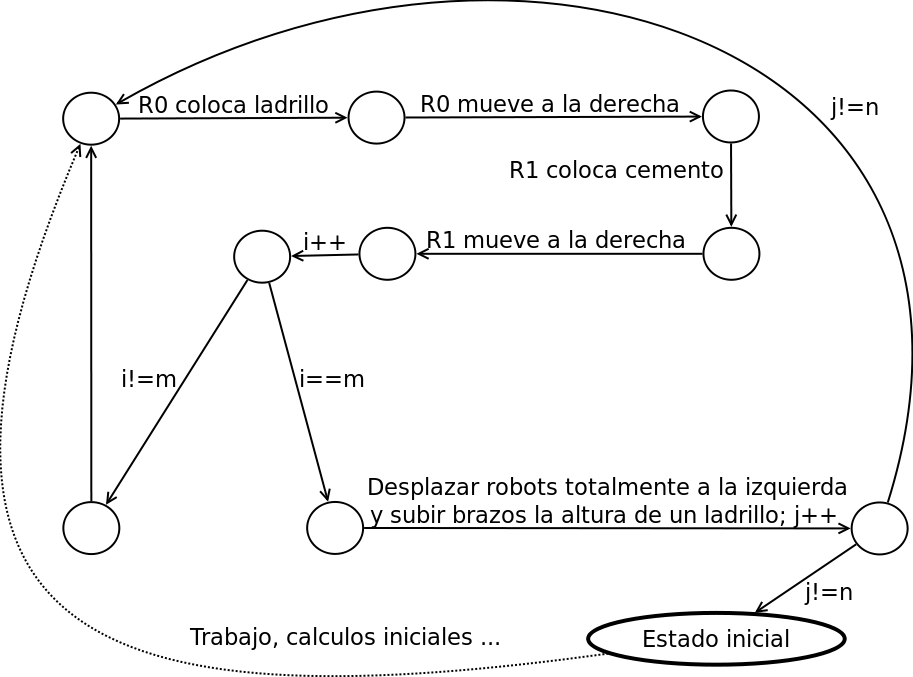
Las reflexiones anteriores constituyeron el inicio de mis investigaciones sobre la validez semántica de un sistema distribuido. A pesar de su poder y de que éstas son bastante objetivas y metódicas, ellas no son suficientes para estudiar cabalmente la eficacia de un sistema. Sin embargo, estas reflexiones me permitieron vislumbrar un método mucho mejor para estudiar la validez semántica de un sistema distribuido. El método se basa en un autómata especial que se ejecuta en paralelo con las transiciones en línea del autómata global y cuyas transiciones son en función del estado del global del sistema. Denominé a esta clase especial de autómata "autómata de seguimiento temporal". Por ejemplo, supongamos dos robots "albañiles" que erigen una pared: Un robot R0 coloca los ladrillos y otro R1 el cemento. Los Robots reciben como entrada el largo y altura de la pared, y se calculan las cantidades de hileras n y de ladrillos por hilera m. Un autómata de seguimiento, reducido, es el mostrado en la figura. Si en algún momento de la exploración del espacio de estado global, el autómata de seguimiento se bloquea, entonces significa que el sistema no cumple con la especificación.
El nombre Sinergia_ω lo propuso Charles Páez. En griego, "sinergia" significa cooperación, mientras que la letra griega ω es un operador muy particular, parecido al operador * de la clausura de Kleene, pero para el tiempo; el operador ω connota la repitencia "infinitamente a menudo".
Mi trabajo de tesis no fue muy difícil en programación; pero fue demasiado aleccionador y enriquecedor; en particular sobre la importancia de una sólida formación en computación.
Si hasta aquí usted me ha leído y logrado entenderme (y yo, por supuesto, explicarme), entonces es muy propicia la ocasión para manifestar mi suma preocupación con algunas recientes opiniones que he escuchado de parte de expertos en autómatas y robótica. Escuché decir a un experto en autómatas que "jamás en su vida" ha requerido de la teoría de grafos. Lo extrañísimo del comentario es que la representación más popular para un autómata es mediante un grafo dirigido y que muchos problemas en autómatas apelan a problemas de grafos. También le he escuchado decir a expertos en robótica opiniones parecidas. Prefiero pensar que estas opiniones son más resultantes de la inexperiencia y de nuestra enorme dependencia en tecnología foránea, que de la negligencia (a pesar de que son rayanas). Sin embargo, en todo caso, nunca, pero nunca, confíe en un dispositivo que haya sido diseñado por ingenieros que exhiben opiniones de este tipo. Piense en montarse en un avión cuyo funcionamiento no ha sido verificado rigurosamente, o en confiar la producción de una fábrica a sistemas robóticos no verificados.
Si Ud. está interesado en este fascinante mundo de la validación estática, entonces le recomiendo Promela/Spin. Este excelente software, ahora bastante maduro y avanzado, se realizaba para la misma época en que yo realizaba Sinergia_ω. Otro punto que es muy importante mencionar, es que ahora hay trabajos en validación estática sobre el propio código; es decir, que validan el software implementado y no su especificación; en ese sentido, recomiendo eche un vistazo a aquí.
Los 90
Sección en curso de construcción
Los 00
Sección en curso de construcción