 |
 |
UNIVERSIDAD DE LOS ANDES
FACULTAD DE INGENIERÍA
POSTGRADO EN COMPUTACIÓN
|
Tema 2. Modelos de objetos
Prof. Isabel Besembel Carrera
Núcleo La Hechicera. Edif. Economía. 3er. piso. Ala 3S. Mérida.
Venezuela.
 Programa del curso
Programa del curso
|
type Empleado is
body
[nombre : string;
trabajaEn : Departamento;
salario : int;
historial : { Cargo }; ]
operations
declare capacitación : -> int;
implementation
define capacitación is
begin
var tc, td : float := 0.0 ;
foreach ( t in self . historial )
begin
tc := tc + t . competencia * t . duración;
td := td + t. duración;
end foreach
return round(tc/td);
end define capacitación;
end type Empleado; |
type Cargo is
body
[ competencia : int;
duración : float; ]
end type Cargo
type Departamento is
body
[ nombre : string;
secretaria : Empleado;
jefe : Gerente ;]
end type Departamento;
type Gerente supertype Empleado is
body
[ regrese : Empleado ;]
end type Gerente; |
Ejemplos de consultas:
|
Q1: |
range e : Empleado
retrieve e
where e.trabajaEn.jefe.salario < 1.200.000 |
Q2: |
range e : Empleado
retrieve e
where e.competencia = 10 |
Q3: |
range e : Empleado
retrieve e.trabajaEn.jefe.salario
where e.nombre = "Perez" |
Un ejemplo de extensiones se puede ver en la figura 1.

Figura 1. Ejemplo de extensiones de la base de datos anterior.
Indización de expresiones de caminos:
- El producto por igualdad de valores de los atributos tiene un rol menos dominante en BDOO. El acceso por cadenas de referencias es más importante (join implícitos).
- Las relaciones de soporte de acceso constituyen materializaciones de las cadenas de referencia más utilizadas.
- Una expresión de camino es o.A1. ... .An
donde o es un objeto cuya estructura es una tupla que contiene el atributo
A1, y o.A1. ... .Ai refieren a un
objeto o a un conjunto de objetos donde todos ellos tienen un atributo Ai+1.
- El resultado de una expresión de camino es un conjunto de objetos o
valores del tipo Tn que puede ser alcanzado desde o a través
de la cadena de atributos especificada.
- Expresión de camino: Sean t0,...,tn
tipos no necesariamente distintos. Una expresión de camino sobre t0
es una expresión t0.A1. ... .An si
para cada 1 < = i < = n una de las dos condiciones se cumple:
1. El tipo ti-1 está definido como type ti-1 is [... , Ai: ti, ...], lo cual indica que ti-1 es una tupla con un atributo Ai en el dominio ti.
2. El tipo ti-1 está definido como type ti-1 is [... , Ai: {ti}, ...], lo cual indica que Ai es un conjunto en el dominio ti. Una ocurrencia de un conjunto en el camino.
Si se cumple 1 la expresión es lineal, de lo contrario es de conjunto.
- Relaciones de soporte de acceso: Sean t0,...,tn tipos y t0.A1. ... .An una expresión de camino. Una relación de soporte de acceso [t0.A1. ... .An] es de aridad n+1 y sus tuplas tienen la forma [S0,...,Sn]
- El dominio del atributo Si es el conjunto de oids de los objetos
de tipo ti con 1 <= i <= n.
Si tn es un tipo átomico, Sn tiene dominio tn, entonces sus valores son almacenados directamente en la RSA.
- Relaciones binarias temporales: Para cada atributo en la expresión de camino se tiene una relación binaria temporal [ti-1.Ai], que contiene las tuplas (oid(Oi-1), oid(Oi)) para cada objeto Oi-1 de tipo ti-1 y Oi de tipo ti tal que:
1. Oi-1.Ai = Oi si Ai es un atributo simplemente valuado
2. Oi pertenece a Oi-1.Ai si Ai es un atributo multivaluado (conjunto)
Ejemplo: P es estrictamente igual a Empleado.trabajaEn.jefe.salario como lo muestra la figura 3.
- Extensiones de las relaciones de soporte de acceso:
La extensión canónica: donatada como [t0.A1,...,An] can contiene información sobre los caminos completos desde t0 hasta tn. Solo puede ser usada para evaluar consultas que se originan en t0 y van a tn.
- Canónica: [t0.A1. ... .An]can
contiene toda la información acerca de los caminos completos,
puede usarse para evaluar consultas que se originan solamente en t0
y van hasta tn.
- Completa a la izquierda: [t0.A1 ... .An]izq contiene todos los caminos que se originan en t0 pero que no necesariamente llegan a tn
- Completa a la derecha: [t0.A1. ... .An]der contiene todos los caminos que llegan a t0 y que posiblemente se originan en un tj.
- Completa: [t0.A1. ... .An]comp contiene todos los caminos parciales, incluso aquellos que no se originan en t0 y que pueden terminar en nulo.
Extensiones: Sea |X| ( ]X[ , ]X| , |X[ ) el producto natural ( externo, externo izquierdo, externo derecho) sobre la última columna de la primera relación y la primera columna de la segunda. Las relaciones anteriores se obtiene con:
[t0.A1. ... .An] can := [t0.A1] |X| ... |X| [tn-1.An]
[t0.A1. ... .An] comp := [t0.A1] ]X[ ... ]X[ [tn-1.An]
[t0.A1. ... .An] izq := (... ([t0.A1] ]X| ... [t1.A2]) ... ]X| [tn-1.An])
[t0.A1. ... .An] der := ([t0.A1] |X[... ([tn-2.An-1] |X[ [tn-1.An]) .... )
La extensión completa contiene más información que las extensiones completas a la izquierda y a la derecha, que a su vez contienen más información que la canónica.
La izquierda y la derecha no son comparables.
[ Empleado . trabajaEn . jefe . salario ] comp
|
S0: Oid Empleado
oid4
oid5
oid6
oid11
------
....... |
S1: Oid Departamento
oid8
oid8
oid9
oid8
oid10
....... |
S2: Oid Gerente
oid11
oid11
oid12
oid11
oid13
....... |
S3: moneda
1.500.000
1.500.000
nulo
1.500.000
2.500.000
....... |
Aplicabilidad: Una RSA [t0.A1. ... .An] X bajo la extensión X es aplicable en el camino s.Ai. ... .Aj, donde s es un subtipo de ti-1 bajo las condiciones siguientes:
|
Aplicable ( [t0.A1. ... .An] X,
s.Ai. ... .Aj ) = |
|
| | | |
X = comp /\ 1 < = i < = j < = n
X = izq /\ 1 = i < = j < = n
X = der /\ 1 < = i < = j = n
X = can /\ 1 = i < = j = n
|
La extension completa puede ser utilizada para evaluar cualquier subcamino,
las izquierda y derecha pueden utilizarse solamente para evaluar prefijos y
sufijos de caminos, respectivamente, y la canónica solo para evaluar
un camino completo.
La estructura de almacenamiento para las RSA está basada en la propuesta de Valduriez 1987 denominada índice de producto binario. Cada RSA se almacena en dos índices, el primero tiene como clave el atributo más a la izquierda y el segundo el atributo más a la derecha. La estructura de los índices pueden ser: tablas hash o árboles_B+. La figura 3 muestra una ilustración de ello.

Figura 3. Uso de índices de acceso con árboles_B+.
El árbol_B+ de la izquierda agrupa hacia adelante y el de la derecha agrupa hacia atrás. El recorrido hacia atrás constituye un semi-producto derecha-a-izquierda:
proyecciónS0 ( [Empleado . trabajaEn . jefe]can
semi-producto a la izquierda( restricción S1 < 200.000
[Gerente.salario]can ) )
El recorrido hacia adelante se corresponde con un semi-producto izquiera-a-derecha:
proyecciónS3 ( ( restricción S0 = oid5
[Empleado . trabajaEn . jefe]can ) semi-producto a la derecha[Gerente
. salario]can )
El índice de caminos de Maier y Stein 1986 se restringe a caminos que
contengan atributos monovaluados y su representación está limitada
a particiones binarias. Los usados en Orion son un caso especial de las RSA.
Índices sobre la jerarquía de tipos
- Los índices pueden verse como un caso especial de las RSA.
- Un índice por tipo: Cada tipo tiene un índice por
el atributo especificado. La figura 4 muestra un ejemplo de este caso.

Figura 4. Ejemplo de índice por tipo.
- Índice sobre la jerarquía de tipos: Consiste de un
árbol_B+ que contiene todas las instancias directas o indirectas del
tipo indexado. Kim, Kim y Dale 1989 modificaron la estructura de las hojas
para contener los desplazamientos para encontrar los Oids de cada tipo, de
la forma mostrada en la figura 5.
|
longitud del registro
|
entrada 1 |
entrada 2 |
|
longitud de clave
|
valor de clave
|
página de desborde |
# Oids |
directorio |
id1, id2, ..., idj |
..... |
donde
| directorio |
| # Tipos |
T1 |
desplazamiento |
T2 |
desplazamiento |
... |
Tn |
desplazamiento |
Figura 5. Ejemplo de índice sobre la jerarquía de tipos.
Low,Ooi y Lu 1992 proponen los árboles_H que son construidos
anidando los árboles_B+, así el índice de un subtipo está
dentro del índice del supertipo. La figura 6 ilustra un ejemplo de estos.

Figura 6. Ejemplo de árboles_H.
El rango de un subárbol referenciado por un apuntador L debe estar contenido
en el rango del árbol del supertipo. Todos los nodos hojas del árbol
del subtipo son cubiertos por el árbol del subtipo.
La función de materialización
- Se modifican y recompilan solamente las clases (tipos) cuyas instancias están involucradas en alguna materialización.
- Relación generalizada de materialización (RGM): Sea t1,
..., tn, tn + 1, ... tn + m unos tipos y f1, ..., fn
unas funciones no transformadoras con fj: t1, ..., tn
-> tn + j, para 1 < = j < = m.
La RGM < f1, ... , fm > para las funciones f1,...,fm es de aridad n + 2 * m y tiene la forma siguiente:
< f1, ... , fm > : [O1:t1, ... , On: tn , f1: tn + 1 V1 : bool, ... , fm: tn + m , Vm : bool]
Oi : son los argumentos, Fi : guardan los resultados y Vi: es la validez de esos resultados.
- Una RGM < f1, ... , fm > es consistente si su indicador de validez es verdadero.
Para todo T que pertenece a < f1, ... , fm > : T . Vj = Verdadero => T . fj = fj (T . O1,..., T . On)
- Si hay una actualización de la BD que invalida un resultado de una función de materialización se puede realizar una:
1. Rematerialización inmediata: El resultado de la función
invalidado se recalcula inmediatamente cada vez que ello ocurra.
2. Rematerialización tardía: El resultado invalidado
de la función se marca como inválido colocando Vi como
falso y ella es recalculada luego cuando se vuelva a cargar el sistema o cuando
esa función se necesite.
Ejemplo: para Q2
< Empleado . competencia >
|
O1: Oid Empleado
oid5
oid6
oid7
......
oid12
oid13 |
competencia : int
7
8
3
.......
8
....... |
V competencia : bool
Verdadero
Verdadero
Verdadero
......
Verdadero
....... |
Proyección O1 ( Restricción competencia = 10
< Empleado . competencia > )
La RGM < Empleado . competencia > contiene una competencia válida
para todas las instancias de Empleado.
- El mejor soporte de acceso para las RGM es un índice multidimensional
sobre los campos O1, ... On, f1, ..., fm.
Son n + m columnas que constituyen las n + m claves del índice (n +
m) - dimensional. Los m bits de validez V1, ..., Vm
son atributos adicionales almacenados en el índice. La estructura archivo
malla de Nievergelt et al. 1984 no arroja rendimientos favorables para más
de 4 dimensiones.
- Invalidación y rematerialización de los resultados de las
funciones: En la mayoría de los modelos las referencias a otros objetos
son unidireccionales. La relación de referencia inversa (RRI) es usada
por el manejador de RGMs para mantener los objetos relacionados con la materialización.
- Relación de referencia inversa: Es un conjunto de tuplas de la forma
[O : Oid, F : Fid, A : List(Oids)]
Las referencias inversas se insertan en la RRI durante los procesos de materialización.
Durante una rematerialización las modificaciones de las funciones son
invocadas. Cada vez que un objeto es actualizado en la base de objetos, la RRI
se inspecciona para determinar cual resultado materializado tiene resultados
inválidos.
- Estrategias para reducir el overhead por invalidación:
- Aislamiento de las propiedades relevantes del objeto: Normalmente los resultados
materializados no dependen sino de una fracción del estado de los objetos
visitados en la materialización. Ejm: la competencia no depende del
sexo del Empleado.
- Reducción de los chequeos de la RRI: Mantener más información
dentro de los objetos para evitar mirar la RRI para todos los objetos actualizados.
- Explotar la encapsulación estricta: Un subobjeto no puede ser actualizado
separadamente de su objeto, por lo que se puede reducir el número de
invalidaciones con el disparo de la invalidación del objeto de alto nivel.
- Compensación de las actualizaciones: En vez de usar la función
de materialización para recalcular un resultado inválido, se pueden
usar acciones compensatorias que usen el resultado viejo y los parámetros
de la actualización para recalcular el nuevo resultado de forma más
eficiente.
Ubicación de los objetos
- El agrupamiento (clustering) es la colocación de objetos relacionados
lógicamente en áreas físicas contiguas. Su efectividad
se mide por el número de faltas de página que ocurren durante
una aplicación. Enfoques: agrupamiento basado en la secuencia y agrupamiento
basado en la partición.
- Agrupamiento basado en la secuencia: Agrupa los objetos en una
secuencia específica en disco. Fases: preordenamiento y recorrido.
En la primera todos los objetos son ordenados y en la segunda, los objetos
ordenados sirven de raíz para el algoritmo de recorrido. Todos los
objetos alcanzables desde el objeto raíz son anexados a la secuencia
de agrupamiento en disco de acuerdo a su orden de visita. Si una secuencia
es muy larga y no cabe en una página, se comienza una nueva secuencia
cuya raíz es el objeto donde se quedó. Cuidar el almacenamiento
doble.
El orden puede ser en base al tiempo de creación del objeto o a uno
especificado por el usuario. Los algoritmos de recorrido son: primero-en-profundidad,
primero-a-lo-ancho y primero-el-mejor.
En primero-el-mejor las referencias tienen un peso. Si se usa 0 y 1 como
pesos, el algortimo puede ser especificado por un árbol de ubicación.
La figura 7 presenta un ejemplo.

Figura 7. Ejemplo de un árbol de ubicación.
- Agrupamiento basado en la partición: Particionar un grafo
en subgrafos disjuntos. Basándose en los pesos de las referencias,
se tienen dos algoritmos:
1. Particionamiento heurístico: Se incia con uno cualquiera,
se itera con cada par intercambiando objetos si el peso total decrece.
Problemas: tamaño de los objetos, espacio inutilizado en las páginas
y O( n 2.4 ).
2. Particionamiento rápido: Basado en el algoritmo de
Kruskal para calcular árboles de expansión mínimos.
- Posibilidades de ubicación de los objetos:
1. a tiempo de creación
2. a tiempo de finalización de la transacción que los crea
3. en cualquier punto en el tiempo
Descomposición y replicación
- Modelo de almacenamiento N-ario (MAN): Los objetos se consideran
tuplas N-arias que comprenden todos los atributos expresados en su estructura,
incluso los heredados. Se pueden almacenar en un único archivo, pero
eso viola el agrupamiento.
- Modelo por descomposición (MAD): Cada valor de atributo
se almacena separadamente, (Oid, atributo, valor) donde valor es un valor
átomico o un Oid. Considerada deficiente para aplicaciones no distribuidas.
- Modelo híbrido (MADP): Los objetos se fragmentan verticalmente
en base a la afinidad de sus atributos (los que siempre se usan en conjunto).
Cuando un atributo debe usarse en más de un fragmento, se replica.
Una fragmentación natural se obtiene de la jerarquía subtipo/supertipo.
Ejemplo:
|
(oid5, nombre, "Perez")
(oid5, trabajaEn, oid9)
(oid5, salario, 90.000)
(oid5, historial, {oid1,oid2}
|
(oid12, nombre, "Compras")
(oid12, trabajaEn, oid9)
(oid12, salario, 190.000)
(oid12, historial, {...})
|
(oid12, nombre, "Compras")
(oid12, regreso, oid6)
|
Otros modelos de almacenamiento físico
Se presentan otros modelos de almacenamiento físico según Willshire
y Kim en [WiK-90]. Para ello se utilizará la base de datos ejemplo
mostrada en la figura 8.

Figura 8. Estructura lógica de la base de datos de ejemplo.
1.- Modelo físico 1:
- Cada instancia está una sola vez en la BD, en la clase más
específica. Ejm: Orion.
- Espacio: No hay duplicación de datos. Costos de espacio mínimo.
- Recuperación de una instancia: Al ser localizada la instancia no
hay necesidad de buscar en otra parte.
- Modificación de un valor en una instancia: Solo se modifica la
instancia escogida.
- Inserción de una nueva instancia: Solo afecta a una clase.
- Eliminación de una instancia: Solo involucra a dicha instancia,
si no hay composición.
- Evolución del esquema: La creación de una nueva clase puede
afectar el almacenamiento, si existen instancias viejas que deban migrar
para mantener el modelo.
- Indexación: Se prefiere un índice por la jerarquía
de clases.
La figura 9 ilustra el almacenamiento de las instancias en el modelo físico
1.
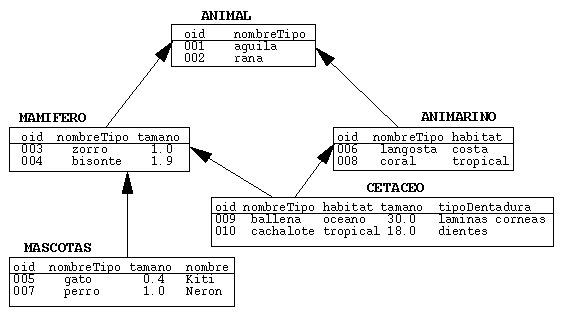
Figura 9. Modelo físico 1.
2.- Modelo físico 2:
- Cada instancia está en cada clase que la utilice.
- Espacio: Duplicación excesiva de datos. Costos de espacio máximo.
- Recuperación de una instancia: Al ser localizada la instancia no
hay necesidad de buscar en otra parte. Preguntas sobre todas las instancias
de una clase se responden sin ir a otro sitio.
- Modificación de un valor en una instancia: Múltiples modificaciones.
- Inserción de una nueva instancia: Múltiples escrituras de
los datos.
- Eliminación de una instancia: Múltiples eliminaciones y
escrituras.
- Evolución del esquema: La creación de una nueva clase implica
escribir datos hacia arriba en la jerarquía. Si se elimina una, implica
múltiples eliminaciones.
- Indexación: Se prefiere un índice por clase.
La figura 8 ilustra el almacenamiento de las instancias en este modelo.
3.- Modelo físico 3:
- Cada instancia almacena el oid y los atributos que le competen. Ejm: Iris.
- Espacio: Duplicación del oid de los datos. Costos de espacio buenos.
- Recuperación de una instancia: Involucra productos de extensiones
de clases por el oid de los objetos.
- Modificación de un valor en una instancia: Hay que acceder la raíz
para conocer oid y luego ubicar al atributo en la clase donde se escribirá.
- Inserción de una nueva instancia: Múltiples escrituras en
las clases adecuadas.
- Eliminación de una instancia: Todas las instancias con igual oid
son eliminadas.
- Evolución del esquema: La creación de una nueva clase no
afecta sino a la jerarquía, donde hay que enlazar la nueva clase.
Eliminación de una clase involucra varias modificaciones en las clases
existentes que usen los oids.
- Indexación: No necesita un índice por la jerarquía
de clases.
La figura 10 presenta el posicionamiento de las instancias para este modelo.

Figura 10. Ejemplo correspondiente al modelo 3.
4.- Modelo físico 4:
- No soporta la noción de clase y ella debe ser deducida por el patrón
de nulos.
- Espacio: Inclusión de un valor nulo. Costos de espacio grande.
- Recuperación de una instancia: Solo se localiza la instancia.
- Modificación de un valor en una instancia: Solo se modifica una
instancia.
- Inserción de una nueva instancia: Se anexa una nueva fila a la
tabla.
- Eliminación de una instancia: Se elimina una fila de la tabla.
- Evolución del esquema: La creación/eliminación de
clases se hace igual que las instancias. Se anexan/eliminan columnas a la
tabla.
- Indexación: Se prefiere un índice por jerarquía de
clases.
|
oid
|
nombreTipo
|
tamaño
|
habitat
|
nombre
|
tipoDentadura
|
|
001
002
003
004
005
006
007
008
009
010
|
águila
rana
zorro
bisonte
gato
langosta
perro
coral
ballena
cachalote
|
nulo
nulo
1.0
1.9
0.4
nulo
1.0
nulo
30.0
18.0
|
nulo
nulo
nulo
nulo
nulo
costa
nulo
tropical
oceano
tropical
|
nulo
nulo
nulo
nulo
Kiti
nulo
Nerón
nulo
nulo
nulo
|
nulo
nulo
nulo
nulo
nulo
nulo
nulo
nulo
láminas córneas
dientes
|
5.- Modelo físico 5:
- Variación del anterior, pero eliminando el uso de valores nulos.
Oids se forman con el identificador de la clase más específica
y su número de instancia. Ejm: Taxis.
- Espacio: Simple relación sin excesivo almacenamiento.
- Recuperación de una instancia: Se recupera el Oid y su valor.
- Modificación de un valor en una instancia: Solo se modifica una
instancia.
- Inserción de una nueva instancia: Se anexa nuevas filas a la tabla.
- Eliminación de una instancia: Se elimina las filas relacionadas
de la tabla.
- Evolución del esquema: La creación/eliminación de
clases hace que sus Oids se creen o eliminen . Se anexan/eliminan filas
a las tablas.
- Indexación: Se prefiere un índice por jerarquía de
clases.
|
ObjectId
|
denota
|
|
01
02
03
04
05
06
07
08
09
10
11
12
|
ANIMAL
MAMIFERO
ANIMARINO
CÉTACEO
MASCOTA
nombreTipo
tamaño
habitat
tipoDentadura
nombre
identificadorInstancia
cualquierCadena
|
MinClase(05008, 05)
Valor(05008, 06, 12001)
Valor(05008, 07, 0.4)
Valor(05008, 10, 12002)
String(12001, "gato")
String(12002, "Kiti")
|
Programa